HuggingFace、GitHub四榜第一!百度 Unlimited OCR 开源 5 天 Star 破万,引爆全球AI圈,百度港股涨超 8%
HuggingFace、GitHub四榜第一!百度 Unlimited OCR 开源 5 天 Star 破万,引爆全球AI圈,百度港股涨超 8%
近日,百度正式发布并开源端到端OCR模型 Unlimited OCR。模型发布后迅速获得全球开发者关注,发布次日即登顶 GitHub Daily Trending 榜、Python榜。随后热度持续攀升,GitHub Star仅 5天就突破1万,跻身 GitHub 现象级爆款项目行列,在HuggingFace全球模型总趋势榜和多模态模型趋势榜也均排名第一,实现GitHub、HuggingFace四榜第一。
与此同时,百度AI在资本市场也迎来积极信号。6月29日,百度集团-SW(09888.HK)股价涨超 8%,据The Information 最新报道,百度旗下昆仑芯正计划赴港上市,目标估值约 500 亿美元。
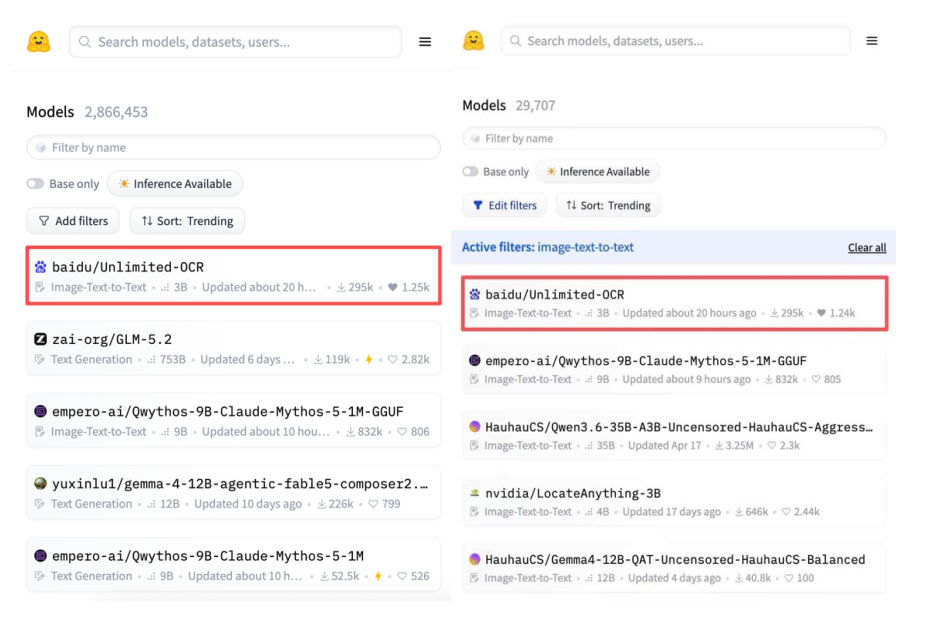
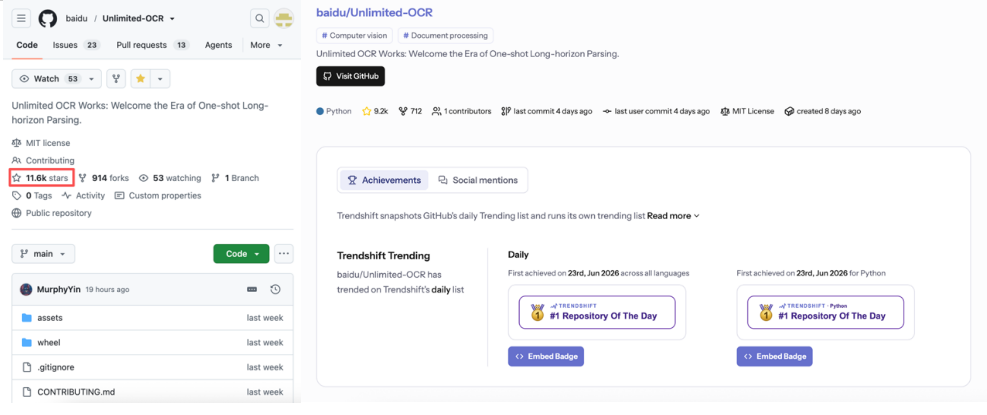
GitHub Star 突破 1 万,一直被视为全球开源项目影响力的重要分水岭,而能够在极短时间内达到这一规模的,通常都是具有现象级关注度的开源项目。Unlimited OCR 仅用 5 天便迈过这一里程碑,展现出强劲的技术实力与全球开发者影响力。
Unlimited OCR 面向长文档解析场景打造,总参数规模 3B、推理时激活参数仅约 570M。公开评测结果显示,Unlimited OCR 在 OmniDocBench v1.6 基准测试中取得 93.92% 综合成绩,刷新端到端 OCR 最新纪录;在保持高精度解析能力的同时,真实文档场景推理速度较 DeepSeek OCR 提升约 12.7%,输出长度达 6000 tokens 时速度优势扩大至 35%。
Unlimited OCR 更重要的意义在于推动了长文档解析技术向前迈出关键一步。过去,OCR 模型面对书籍、论文、报告等长文档时,通常需要采用“逐页解析+结果拼接”的工程方案,随着输出内容不断增长,解码阶段的 KV Cache 持续膨胀,推理速度和显存成本也随之增加。
针对这一行业痛点,百度提出 Reference Sliding Window Attention (R-SWA) 机制,为长程解析提供了新的解决思路。该机制借鉴人类阅读和抄录长文档时的工作方式:始终保持对原始文档内容的关注,同时仅保留最近一段生成内容作为“工作记忆”,而不是无限累积全部历史信息。基于这一设计,模型能够在一次前向推理中连续完成数十页文档解析,实现从第一页到最后一页的连贯输出,同时将解码阶段的 KV Cache 控制在恒定规模,使计算成本和显存占用不随输出长度持续增长。
这一突破不仅提升了 OCR 在长文档场景下的可用性,也为大模型长期记忆管理提供了新的技术思路。近年来,行业普遍通过扩展上下文窗口来增强长程能力,而 Unlimited OCR 则探索了另一条路径——通过更高效的注意力机制和记忆管理策略,让模型“学会保留关键上下文、适度遗忘历史信息”,以更稳定、更经济的方式完成超长任务。
Unlimited OCR 展现的不仅是一项 OCR 能力升级,更是百度在多模态基础模型和长程推理方向上的一次重要探索,为行业提供了处理超长上下文的新思路。
编辑:颜甲 值班主任:田艳敏
